Наряду с изучением вариации признака по всей по всей совокупности в целом часто бывает необходимо проследить количественные изменения признака по группам, на которые разделяется совокупность, а также и между группами. Такое изучение вариации достигается посредством вычисления и анализа различных видов дисперсии.
Выделяют дисперсию общую, межгрупповую и внутригрупповую
.
Общая дисперсия σ 2
измеряет вариацию признака по всей совокупности под влиянием всех факторов, обусловивших эту вариацию, .
Межгрупповая дисперсия (δ) характеризует систематическую вариацию, т.е. различия в величине изучаемого признака, возникающие под влиянием признака-фактора, положенного в основание группировки. Она рассчитывается по формуле:
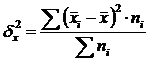 .
.
Внутригрупповая дисперсия (σ)
отражает случайную вариацию, т.е. часть вариации, происходящую под влиянием неучтенных факторов и не зависящую от признака-фактора, положенного в основание группировки. Она вычисляется по формуле:
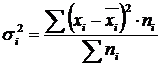 .
.
Средняя из внутригрупповых дисперсий
:  .
.
Существует закон, связывающий 3 вида дисперсии. Общая дисперсия равна сумме средней из внутригрупповых и межгрупповой дисперсии: ![]() .
.
Данное соотношение называют правилом сложения дисперсий
.
В анализе широко используется показатель, представляющий собой долю межгрупповой дисперсии в общей дисперсии. Он носит название эмпирического коэффициента детерминации (η 2):
.
Корень квадратный из эмпирического коэффициента детерминации носит название эмпирического корреляционного отношения (η)
:
 .
.
Оно характеризует влияние признака, положенного в основание группировки, на вариацию результативного признака. Эмпирическое корреляционное отношение изменяется в пределах от 0 до 1.
Покажем его практическое использование на следующем примере (табл. 1).
Пример №1 . Таблица 1 - Производительность труда двух групп рабочих одного из цехов НПО «Циклон»
Рассчитаем общую и групповые средние и дисперсии:
Исходные данные для вычисления средней из внутригрупповых и межгрупповой дисперсии представлены в табл. 2.
Таблица 2
Расчет и δ 2 по двум группам рабочих.
|
Группы рабочих | Численность рабочих, чел. | Средняя, дет./смен. | Дисперсия |
| Прошедшие техническое обучение | 5 | 95 | 42,0 |
| Не прошедшие техническое обучение | 5 | 81 | 231,2 |
| Все рабочие | 10 | 88 | 185,6 |
 .
.
Межгрупповая дисперсия
Общая дисперсия:
Таким образом, эмпирическое корреляционное соотношение: .
Наряду с вариацией количественных признаков может наблюдаться и вариация качественных признаков. Такое изучение вариации достигается посредством вычисления следующих видов дисперсий:
Внутригрупповая дисперсия доли определяется по формуле
где n i – численность единиц в отдельных группах.Доля изучаемого признака во всей совокупности, которая определяется по формуле:
Три вида дисперсии связаны между собой следующим образом:
Это соотношение дисперсий называется теоремой сложения дисперсий доли признака.
Вычислим в MS EXCEL дисперсию и стандартное отклонение выборки. Также вычислим дисперсию случайной величины, если известно ее распределение.
Сначала рассмотрим дисперсию , затем стандартное отклонение .
Дисперсия выборки
Дисперсия выборки (выборочная дисперсия, sample variance ) характеризует разброс значений в массиве относительно .
Все 3 формулы математически эквивалентны.
Из первой формулы видно, что дисперсия выборки это сумма квадратов отклонений каждого значения в массиве от среднего , деленная на размер выборки минус 1.
дисперсии выборки используется функция ДИСП() , англ. название VAR, т.е. VARiance. С версии MS EXCEL 2010 рекомендуется использовать ее аналог ДИСП.В() , англ. название VARS, т.е. Sample VARiance. Кроме того, начиная с версии MS EXCEL 2010 присутствует функция ДИСП.Г(), англ. название VARP, т.е. Population VARiance, которая вычисляет дисперсию для генеральной совокупности . Все отличие сводится к знаменателю: вместо n-1 как у ДИСП.В() , у ДИСП.Г() в знаменателе просто n. До MS EXCEL 2010 для вычисления дисперсии генеральной совокупности использовалась функция ДИСПР() .
Дисперсию выборки
=КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1)
=(СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/ (СЧЁТ(Выборка)-1)
– обычная формула
=СУММ((Выборка -СРЗНАЧ(Выборка))^2)/ (СЧЁТ(Выборка)-1
) –
Дисперсия выборки равна 0, только в том случае, если все значения равны между собой и, соответственно, равны среднему значению . Обычно, чем больше величина дисперсии , тем больше разброс значений в массиве.
Дисперсия выборки является точечной оценкой дисперсии распределения случайной величины, из которой была сделана выборка . О построении доверительных интервалов при оценке дисперсии можно прочитать в статье .
Дисперсия случайной величины
Чтобы вычислить дисперсию случайной величины, необходимо знать ее .
Для дисперсии случайной величины Х часто используют обозначение Var(Х). Дисперсия равна квадрата отклонения от среднего E(X): Var(Х)=E[(X-E(X)) 2 ]
дисперсия вычисляется по формуле:

где x i – значение, которое может принимать случайная величина, а μ – среднее значение (), р(x) – вероятность, что случайная величина примет значение х.
Если случайная величина имеет , то дисперсия вычисляется по формуле:

Размерность дисперсии соответствует квадрату единицы измерения исходных значений. Например, если значения в выборке представляют собой измерения веса детали (в кг), то размерность дисперсии будет кг 2 . Это бывает сложно интерпретировать, поэтому для характеристики разброса значений чаще используют величину равную квадратному корню из дисперсии – стандартное отклонение .
Некоторые свойства дисперсии :
Var(Х+a)=Var(Х), где Х - случайная величина, а - константа.
Var(aХ)=a 2 Var(X)
Var(Х)=E[(X-E(X)) 2 ]=E=E(X 2)-E(2*X*E(X))+(E(X)) 2 =E(X 2)-2*E(X)*E(X)+(E(X)) 2 =E(X 2)-(E(X)) 2
Это свойство дисперсии используется в статье про линейную регрессию .
Var(Х+Y)=Var(Х) + Var(Y) + 2*Cov(Х;Y), где Х и Y - случайные величины, Cov(Х;Y) - ковариация этих случайных величин.
Если случайные величины независимы (independent), то их ковариация равна 0, и, следовательно, Var(Х+Y)=Var(Х)+Var(Y). Это свойство дисперсии используется при выводе .
Покажем, что для независимых величин Var(Х-Y)=Var(Х+Y). Действительно, Var(Х-Y)= Var(Х-Y)= Var(Х+(-Y))= Var(Х)+Var(-Y)= Var(Х)+Var(-Y)= Var(Х)+(-1) 2 Var(Y)= Var(Х)+Var(Y)= Var(Х+Y). Это свойство дисперсии используется для построения .
Стандартное отклонение выборки
Стандартное отклонение выборки - это мера того, насколько широко разбросаны значения в выборке относительно их .
По определению, стандартное отклонение равно квадратному корню из дисперсии :

Стандартное отклонение не учитывает величину значений в выборке , а только степень рассеивания значений вокруг их среднего . Чтобы проиллюстрировать это приведем пример.
Вычислим стандартное отклонение для 2-х выборок: (1; 5; 9) и (1001; 1005; 1009). В обоих случаях, s=4. Очевидно, что отношение величины стандартного отклонения к значениям массива у выборок существенно отличается. Для таких случаев используется Коэффициент вариации (Coefficient of Variation, CV) - отношение Стандартного отклонения к среднему арифметическому , выраженного в процентах.
В MS EXCEL 2007 и более ранних версиях для вычисления Стандартного отклонения выборки используется функция =СТАНДОТКЛОН() , англ. название STDEV, т.е. STandard DEViation. С версии MS EXCEL 2010 рекомендуется использовать ее аналог =СТАНДОТКЛОН.В() , англ. название STDEV.S, т.е. Sample STandard DEViation.
Кроме того, начиная с версии MS EXCEL 2010 присутствует функция СТАНДОТКЛОН.Г() , англ. название STDEV.P, т.е. Population STandard DEViation, которая вычисляет стандартное отклонение для генеральной совокупности . Все отличие сводится к знаменателю: вместо n-1 как у СТАНДОТКЛОН.В() , у СТАНДОТКЛОН.Г() в знаменателе просто n.
Стандартное отклонение
можно также вычислить непосредственно по нижеуказанным формулам (см. файл примера
)
=КОРЕНЬ(КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1))
=КОРЕНЬ((СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/(СЧЁТ(Выборка)-1))
Другие меры разброса
Функция КВАДРОТКЛ() вычисляет сумму квадратов отклонений значений от их среднего . Эта функция вернет тот же результат, что и формула =ДИСП.Г(Выборка )*СЧЁТ(Выборка ) , где Выборка - ссылка на диапазон, содержащий массив значений выборки (). Вычисления в функции КВАДРОТКЛ() производятся по формуле:

Функция СРОТКЛ() является также мерой разброса множества данных. Функция СРОТКЛ() вычисляет среднее абсолютных значений отклонений значений от среднего . Эта функция вернет тот же результат, что и формула =СУММПРОИЗВ(ABS(Выборка-СРЗНАЧ(Выборка)))/СЧЁТ(Выборка) , где Выборка - ссылка на диапазон, содержащий массив значений выборки.
Вычисления в функции СРОТКЛ () производятся по формуле:

Дисперсией (рассеянием) случайной величины называется математическое ожидание квадрата отклонения случайной величины от ее математического ожидания:
Для вычисления дисперсии можно использовать слегка преобразованную формулу
так как М(Х)
, 2 и –
постоянные величины. Таким образом,
–
постоянные величины. Таким образом,
4.2.2. Свойства дисперсии
Свойство 1. Дисперсия постоянной величины равна нулю. Действительно, по определению
Свойство 2. Постоянный множитель можно выносить за знак дисперсии с возведением его в квадрат.
Доказательство
Центрированной случайной величиной называется отклонение случайной величины от ее математического ожидания:

Центрированная величина обладает двумя удобными для преобразования свойствами:
Свойство 3. Если случайные величины Х иY независимы, то
Доказательство
. Обозначим .
Тогдаи.
.
Тогдаи.
Во втором слагаемом в силу независимости случайных величин и свойств центрированных случайных величин
Пример 4.5.
Еслиa
иb
– постоянные,
тоD(a
Х+
b
)=
D
(a
Х)+
D
(b
)= .
.
4.2.3. Среднее квадратическое отклонение
Дисперсия, как
характеристика разброса случайной
величины, имеет один недостаток. Если,
например, Х
– ошибка измерения имеет размерность
ММ
,
то дисперсия имеет размерность
 .
Поэтому часто предпочитают пользоваться
другой характеристикой разброса –средним
квадратическим отклонением
,
которое равно корню квадратному из
дисперсии
.
Поэтому часто предпочитают пользоваться
другой характеристикой разброса –средним
квадратическим отклонением
,
которое равно корню квадратному из
дисперсии

Среднее квадратическое отклонение имеет ту же размерность, что и сама случайная величина.
Пример 4.6. Дисперсия числа появления события в схеме независимых испытаний
Производится n независимых испытаний и вероятность появления события в каждом испытании равнар . Выразим, как и прежде, число появления событияХ через число появления события в отдельных опытах:
Так как опыты независимы, то и связанные
с опытами случайные величины
 независимы. А в силу независимости
независимы. А в силу независимости имеем
имеем
Но каждая из случайных величин имеет закон распределения (пример 3.2)
|
| ||

и
 (пример 4.4). Поэтому, по определению
дисперсии:
(пример 4.4). Поэтому, по определению
дисперсии:
где q =1- p .
В итоге имеем
 ,
,
Среднее квадратическое отклонение
числа появлений события в n
независимых опытах равно .
.
4.3. Моменты случайных величин
Помимо уже рассмотренных случайные величины имеют множество других числовых характеристик.
Начальным
моментом
k
Х
( )
называется математическое ожиданиеk
-й
степени этой случайной величины.
)
называется математическое ожиданиеk
-й
степени этой случайной величины.
Центральным моментом k -го порядка случайной величиныХ называется математическое ожиданиеk -ой степени соответствующей центрированной величины.

Легко видеть, что центральный момент первого порядка всегда равен нулю, центральный момент второго порядка равен дисперсии, так как .
Центральный момент третьего порядка дает представление об асимметрии распределения случайной величины. Моменты порядка выше второго употребляются сравнительно редко, поэтому мы ограничимся только самими понятиями о них.
4.4. Примеры нахождения законов распределения
Рассмотрим примеры нахождения законов распределения случайных величин и их числовых характеристик.
Пример 4.7.
Составить закон распределения числа
попаданий в цель при трех выстрелах по
мишени, если вероятность попадания при
каждом выстреле равна 0,4. Найти интегральную
функцию F
(х)
для
полученного распределения дискретной
случайной величиныХ
и начертить
ее график. Найти математическое ожиданиеM
(X
)
,
дисперсиюD
(X
)
и среднее квадратическое отклонение
 (Х
)
случайной величиныX
.
(Х
)
случайной величиныX
.
Решение
1) Дискретная случайная величина Х – число попаданий в цель при трех выстрелах – может принимать четыре значения:0, 1, 2, 3 . Вероятность того, что она примет каждое из них, найдем по формуле Бернулли при:n =3,p =0,4,q =1- p =0,6 иm =0, 1, 2, 3:
Получим вероятности возможных значений Х :;
Составим искомый закон распределения случайной величины Х :
Контроль: 0,216+0,432+0,288+0,064=1.
Построим многоугольник распределения полученной случайной величины Х . Для этого в прямоугольной системе координат отметим точки (0; 0,216), (1; 0,432), (2; 0,288), (3; 0,064). Соединим эти точки отрезками прямых, полученная ломаная и есть искомый многоугольник распределения (рис. 4.1).

2) Если х 0,
то F
(х)
=0.
Действительно, значений, меньших нуля,
величина Х
не принимает. Следовательно, при всех
х
0,
то F
(х)
=0.
Действительно, значений, меньших нуля,
величина Х
не принимает. Следовательно, при всех
х
 0
, пользуясь определениемF
(х)
,
получим F
(х)
=P
(X
<
x
)
=0
(как вероятность невозможного события).
0
, пользуясь определениемF
(х)
,
получим F
(х)
=P
(X
<
x
)
=0
(как вероятность невозможного события).
Если 0 ,
тоF
(X
)
=0,216.
Действительно, в этом случаеF
(х)
=P
(X
<
x
)
=
=P
(-
,
тоF
(X
)
=0,216.
Действительно, в этом случаеF
(х)
=P
(X
<
x
)
=
=P
(-
 <
X
<
X 0)+
P
(0<
X
<
x
)
=0,216+0=0,216.
0)+
P
(0<
X
<
x
)
=0,216+0=0,216.
Если взять, например, х =0,2, тоF (0,2)=P (X <0,2) . Но вероятность событияХ <0,2 равна 0,216, так как случайная величинаХ лишь в одном случае принимает значение меньшее 0,2, а именно0 с вероятностью 0,216.
Если 1 ,
то
,
то
Действительно, Х может принять значение 0 с вероятностью 0,216 и значение 1 с вероятностью 0,432; следовательно, одно из этих значений, безразлично какое,Х может принять (по теореме сложения вероятностей несовместных событий) с вероятностью 0,648.
Если 2 ,
то рассуждая аналогично, получимF
(х)
=0,216+0,432 +
+ 0,288=0,936. Действительно, пусть, например,х
=3. ТогдаF
(3)=P
(X
<3)
выражает вероятность событияX
<3 –
стрелок сделает меньше трех попаданий,
т.е. ноль, один или два. Применяя теорему
сложения вероятностей, получим указанное
значение функцииF
(х)
.
,
то рассуждая аналогично, получимF
(х)
=0,216+0,432 +
+ 0,288=0,936. Действительно, пусть, например,х
=3. ТогдаF
(3)=P
(X
<3)
выражает вероятность событияX
<3 –
стрелок сделает меньше трех попаданий,
т.е. ноль, один или два. Применяя теорему
сложения вероятностей, получим указанное
значение функцииF
(х)
.
Если x
>3, тоF
(х)
=0,216+0,432+0,288+0,064=1.
Действительно, событиеX
 является
достоверным и вероятность его равна
единице, аX
>3 –
невозможным. Учитывая, что
является
достоверным и вероятность его равна
единице, аX
>3 –
невозможным. Учитывая, что
F
(х)
=P
(X
<
x
)
=P
(X 3)
+
P
(3<
X
<
x
)
,
получим указанный результат.
3)
+
P
(3<
X
<
x
)
,
получим указанный результат.
Итак, получена искомая интегральная функция распределения случайной величины Х:
F
(x
)
=

график которой изображен на рис. 4.2.

3) Математическое ожидание дискретной случайной величины равно сумме произведений всех возможных значений Х на их вероятности:
М(Х) =0=1,2.
То есть, в среднем происходит одно попадание в цель при трех выстрелах.
Дисперсию можно вычислить, исходя из
определения дисперсии D
(X
)=
M
(X
-
M
(X
))
 или воспользоваться формулойD
(X
)=
M
(X
или воспользоваться формулойD
(X
)=
M
(X ,
которая ведет к цели быстрее.
,
которая ведет к цели быстрее.
Напишем закон распределения случайной
величины Х :
:
Найдем математическое ожидание для Х
 :
:
М(Х )
= 04
)
= 04 = 2,16.
= 2,16.
Вычислим искомую дисперсию:
D
(X
)
=
M
(X )
– (M
(X
))
)
– (M
(X
))
 = 2,16 – (1,2)
= 2,16 – (1,2) = 0,72.
= 0,72.
Среднее квадратическое отклонение найдем по формуле
 (X
)
=
(X
)
=
 = 0,848.
= 0,848.
Интервал (M
-
 ;
M
+
;
M
+
 )
= (1,2-0,85; 1,2+0,85) = (0,35; 2,05) – интервал
наиболее вероятных значений случайной
величиныХ
, в него попадают значения
1 и 2.
)
= (1,2-0,85; 1,2+0,85) = (0,35; 2,05) – интервал
наиболее вероятных значений случайной
величиныХ
, в него попадают значения
1 и 2.
Пример 4.8.
Дана дифференциальная функция распределения (функция плотности) непрерывной случайной величины Х :
 f
(x
)
=
f
(x
)
=
1) Определить постоянный параметр a .
2) Найти интегральную функцию F (x ) .
3) Построить графики функций f (x ) иF (x ) .
4) Найти двумя способами вероятности
Р(0,5<
X 1,5)
иP
(1,5<
X
<3,5)
.
1,5)
иP
(1,5<
X
<3,5)
.
5). Найти математическое ожидание М(Х)
,
дисперсиюD
(Х)
и
среднее квадратическое отклонение
 случайной величиныХ
.
случайной величиныХ
.
Решение
1) Дифференциальная функция по свойству
f
(x
)
должна удовлетворять условию .
.
Вычислим этот несобственный интеграл для данной функции f (x ) :

Подставляя этот результат в левую часть
равенства, получим, что а
=1. В условии
дляf
(x
)
заменим параметра
на 1:

2) Для нахождения F (x ) воспользуемся формулой
 .
.
Если х ,
то
,
то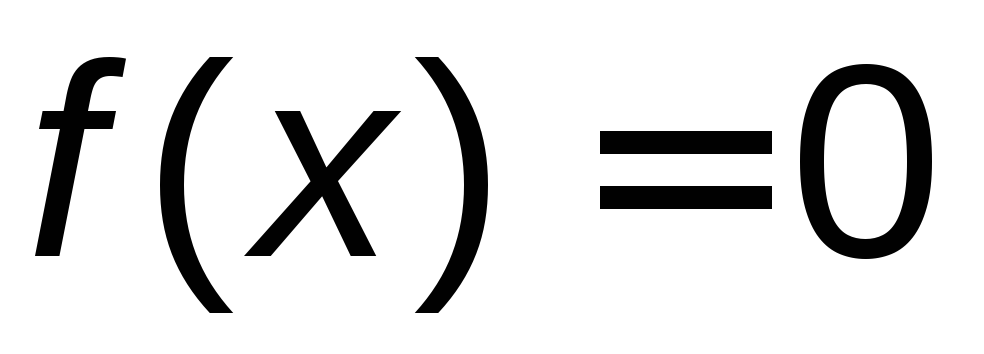 ,
следовательно,
,
следовательно,
Если 1 то
то
Если x>2, то
Итак, искомая интегральная функция F (x ) имеет вид:

3) Построим графики функций f (x ) иF (x ) (рис. 4.3 и 4.4).


4) Вероятность попадания случайной
величины в заданный интервал (а,
b
)
вычисляется по формуле
 ,
если известнафункция
f
(x
),
и по формуле P
(a
<
X
<
b
)
=
F
(b
)
–
F
(a
),
если известна
функция
F
(x
).
,
если известнафункция
f
(x
),
и по формуле P
(a
<
X
<
b
)
=
F
(b
)
–
F
(a
),
если известна
функция
F
(x
).
Найдем
 по двум формулам и сравним результаты.
По условиюа=0,5;
b
=1,5;
функцияf
(X
)
задана в пункте 1). Следовательно,
искомая вероятность по формуле равна:
по двум формулам и сравним результаты.
По условиюа=0,5;
b
=1,5;
функцияf
(X
)
задана в пункте 1). Следовательно,
искомая вероятность по формуле равна:
Та же вероятность может быть вычислена по формуле b) через приращение полученной в п.2). интегральной функцииF (x ) на этом интервале:
Так какF (0,5)=0.
Аналогично находим
так как F (3,5)=1.
5) Для нахождения математического
ожидания М(Х)
воспользуемся формулой
 Функцияf
(x
)
задана в решении пункта 1), она равна
нулю вне интервала (1,2]:
Функцияf
(x
)
задана в решении пункта 1), она равна
нулю вне интервала (1,2]:

 Дисперсия
непрерывной случайной величиныD
(Х)
определяется равенством
Дисперсия
непрерывной случайной величиныD
(Х)
определяется равенством
 ,
или равносильным равенством
,
или равносильным равенством

 .
.
Для нахожденияD
(X
)
воспользуемся последней формулой и
учтем, что все возможные значенияf
(x
)
принадлежат интервалу (1,2]:
нахожденияD
(X
)
воспользуемся последней формулой и
учтем, что все возможные значенияf
(x
)
принадлежат интервалу (1,2]:
Среднее квадратическое отклонение
 =
= =0,276.
=0,276.
Интервал наиболее вероятных значений случайной величины Х равен
(М- ,М+
,М+ )
= (1,58-0,28; 1,58+0,28) = (1,3; 1,86).
)
= (1,58-0,28; 1,58+0,28) = (1,3; 1,86).
Математическое ожидание и дисперсия - чаще всего применяемые числовые характеристики случайной величины. Они характеризуют самые важные черты распределения: его положение и степень разбросанности. Во многих задачах практики полная, исчерпывающая характеристика случайной величины - закон распределения - или вообще не может быть получена, или вообще не нужна. В этих случаях ограничиваются приблизительным описанием случайной величины с помощью числовых характеристик.
Математическое ожидание часто называют просто средним значением случайной величины. Дисперсия случайной величины - характеристика рассеивания, разбросанности случайной величины около её математического ожидания.
Математическое ожидание дискретной случайной величины
Подойдём к понятию математического ожидания, сначала исходя из механической интерпретации распределения дискретной случайной величины. Пусть единичная масса распределена между точками оси абсцисс x 1 , x 2 , ..., x n , причём каждая материальная точка имеет соответствующую ей массу из p 1 , p 2 , ..., p n . Требуется выбрать одну точку на оси абсцисс, характеризующую положение всей системы материальных точек, с учётом их масс. Естественно в качестве такой точки взять центр массы системы материальных точек. Это есть среднее взвешенное значение случайной величины X , в которое абсцисса каждой точки x i входит с "весом", равным соответствующей вероятности. Полученное таким образом среднее значение случайной величины X называется её математическим ожиданием.
Математическим ожиданием дискретной случайной величины называется сумма произведений всех возможных её значений на вероятности этих значений:
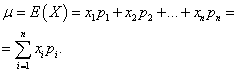
Пример 1. Организована беспроигрышная лотерея. Имеется 1000 выигрышей, из них 400 по 10 руб. 300 - по 20 руб. 200 - по 100 руб. и 100 - по 200 руб. Каков средний размер выигрыша для купившего один билет?
Решение. Средний выигрыш мы найдём, если общую сумму выигрышей, которая равна 10*400 + 20*300 + 100*200 + 200*100 = 50000 руб, разделим на 1000 (общая сумма выигрышей). Тогда получим 50000/1000 = 50 руб. Но выражение для подсчёта среднего выигрыша можно представить и в следующем виде:
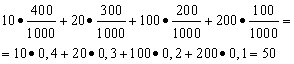
С другой стороны, в данных условиях размер выигрыша является случайной величиной, которая может принимать значения 10, 20, 100 и 200 руб. с вероятностями, равными соответственно 0,4; 0,3; 0,2; 0,1. Следовательно, ожидаемый средний выигрыш равен сумме произведений размеров выигрышей на вероятности их получения.
Пример 2. Издатель решил издать новую книгу. Продавать книгу он собирается за 280 руб., из которых 200 получит он сам, 50 - книжный магазин и 30 - автор. В таблице дана информация о затратах на издание книги и вероятности продажи определённого числа экземпляров книги.
Найти ожидаемую прибыль издателя.
Решение. Случайная величина "прибыль" равна разности доходов от продажи и стоимости затрат. Например, если будет продано 500 экземпляров книги, то доходы от продажи равны 200*500=100000, а затраты на издание 225000 руб. Таким образом, издателю грозит убыток размером в 125000 руб. В следующей таблице обобщены ожидаемые значения случайной величины - прибыли:
| Число | Прибыль x i | Вероятность p i | x i p i |
| 500 | -125000 | 0,20 | -25000 |
| 1000 | -50000 | 0,40 | -20000 |
| 2000 | 100000 | 0,25 | 25000 |
| 3000 | 250000 | 0,10 | 25000 |
| 4000 | 400000 | 0,05 | 20000 |
| Всего: | 1,00 | 25000 |
Таким образом, получаем математическое ожидание прибыли издателя:
![]() .
.
Пример 3. Вероятность попадания при одном выстреле p = 0,2 . Определить расход снарядов, обеспечивающих математическое ожидание числа попаданий, равное 5.
Решение. Из всё той же формулы математического ожидания, которую мы использовали до сих пор, выражаем x - расход снарядов:
![]() .
.
Пример 4. Определить математическое ожидание случайной величины x числа попаданий при трёх выстрелах, если вероятность попадания при каждом выстреле p = 0,4 .
Подсказка: вероятность значений случайной величины найти по формуле Бернулли .
Свойства математического ожидания
Рассмотрим свойства математического ожидания.
Свойство 1. Математическое ожидание постоянной величины равно этой постоянной:
Свойство 2. Постоянный множитель можно выносить за знак математического ожидания:
![]()
Свойство 3. Математическое ожидание суммы (разности) случайных величин равно сумме (разности) их математических ожиданий:
Свойство 4. Математическое ожидание произведения случайных величин равно произведению их математических ожиданий:
Свойство 5. Если все значения случайной величины X уменьшить (увеличить) на одно и то же число С , то её математическое ожидание уменьшится (увеличится) на то же число:
![]()
Когда нельзя ограничиваться только математическим ожиданием
В большинстве случаев только математическое ожидание не может в достаточной степени характеризовать случайную величину.
Пусть случайные величины X и Y заданы следующими законами распределения:
| Значение X | Вероятность |
| -0,1 | 0,1 |
| -0,01 | 0,2 |
| 0 | 0,4 |
| 0,01 | 0,2 |
| 0,1 | 0,1 |
| Значение Y | Вероятность |
| -20 | 0,3 |
| -10 | 0,1 |
| 0 | 0,2 |
| 10 | 0,1 |
| 20 | 0,3 |
Математические ожидания этих величин одинаковы - равны нулю:
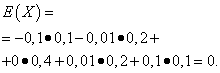
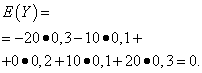
Однако характер распределения их различный. Случайная величина X может принимать только значения, мало отличающиеся от математического ожидания, а случайная величина Y может принимать значения, значительно отклоняющиеся от математического ожидания. Аналогичный пример: средняя заработная плата не даёт возможности судить об удельном весе высоко- и низкооплачиваемых рабочих. Иными словами, по математическому ожиданию нельзя судить о том, какие отклонения от него, хотя бы в среднем, возможны. Для этого нужно найти дисперсию случайной величины.
Дисперсия дискретной случайной величины
Дисперсией дискретной случайной величины X называется математическое ожидание квадрата отклонения её от математического ожидания:
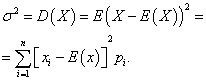
Средним квадратическим отклонением случайной величины X называется арифметическое значение квадратного корня её дисперсии:
![]() .
.
Пример 5. Вычислить дисперсии и средние квадратические отклонения случайных величин X и Y , законы распределения которых приведены в таблицах выше.
Решение. Математические ожидания случайных величин X и Y , как было найдено выше, равны нулю. Согласно формуле дисперсии при Е (х )=Е (y )=0 получаем:

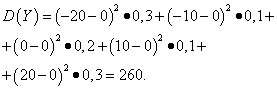
Тогда средние квадратические отклонения случайных величин X и Y составляют
![]() .
.
Таким образом, при одинаковых математических ожиданиях дисперсия случайной величины X очень мала, а случайной величины Y - значительная. Это следствие различия в их распределении.
Пример 6. У инвестора есть 4 альтернативных проекта инвестиций. В таблице обобщены данные об ожидаемой прибыли в этих проектах с соответствующей вероятностью.
| Проект 1 | Проект 2 | Проект 3 | Проект 4 |
| 500, P =1 | 1000, P =0,5 | 500, P =0,5 | 500, P =0,5 |
| 0, P =0,5 | 1000, P =0,25 | 10500, P =0,25 | |
| 0, P =0,25 | 9500, P =0,25 |
Найти для каждой альтернативы математическое ожидание, дисперсию и среднее квадратическое отклонение.
Решение. Покажем, как вычисляются эти величины для 3-й альтернативы:
В таблице обобщены найденные величины для всех альтернатив.
У всех альтернатив одинаковы математические ожидания. Это означает, что в долгосрочном периоде у всех - одинаковые доходы. Стандартное отклонение можно интерпретировать как единицу измерения риска - чем оно больше, тем больше риск инвестиций. Инвестор, который не желает большого риска, выберет проект 1, так как у него наименьшее стандартное отклонение (0). Если же инвестор отдаёт предпочтение риску и большим доходам в короткий период, то он выберет проект наибольшим стандартным отклонением - проект 4.
Свойства дисперсии
Приведём свойства дисперсии.
Свойство 1. Дисперсия постоянной величины равна нулю:
Свойство 2. Постоянный множитель можно выносить за знак дисперсии, возводя его при этом в квадрат:
![]() .
.
Свойство 3. Дисперсия случайной величины равна математическому ожиданию квадрата этой величины, из которого вычтен квадрат математического ожидания самой величины:
![]() ,
,
где ![]() .
.
Свойство 4. Дисперсия суммы (разности) случайных величин равна сумме (разности) их дисперсий:
Пример 7. Известно, что дискретная случайная величина X принимает лишь два значения: −3 и 7. Кроме того, известно математическое ожидание: E (X ) = 4 . Найти дисперсию дискретной случайной величины.
Решение. Обозначим через p вероятность, с которой случайная величина принимает значение x 1 = −3 . Тогда вероятностью значения x 2 = 7 будет 1 − p . Выведем уравнение для математического ожидания:
E (X ) = x 1 p + x 2 (1 − p ) = −3p + 7(1 − p ) = 4 ,
откуда получаем вероятности: p = 0,3 и 1 − p = 0,7 .
Закон распределения случайной величины:
| X | −3 | 7 |
| p | 0,3 | 0,7 |
Дисперсию данной случайной величины вычислим по формуле из свойства 3 дисперсии:
D (X ) = 2,7 + 34,3 − 16 = 21 .
Найти математическое ожидание случайной величины самостоятельно, а затем посмотреть решение
Пример 8. Дискретная случайная величина X принимает лишь два значения. Большее из значений 3 она принимает с вероятностью 0,4. Кроме того, известна дисперсия случайной величины D (X ) = 6 . Найти математическое ожидание случайной величины.
Пример 9. В урне 6 белых и 4 чёрных шара. Из урны вынимают 3 шара. Число белых шаров среди вынутых шаров является дискретной случайной величиной X . Найти математическое ожидание и дисперсию этой случайной величины.
Решение. Случайная величина X может принимать значения 0, 1, 2, 3. Соответствующие им вероятности можно вычислить по правилу умножения вероятностей . Закон распределения случайной величины:
| X | 0 | 1 | 2 | 3 |
| p | 1/30 | 3/10 | 1/2 | 1/6 |
Отсюда математическое ожидание данной случайной величины:
M (X ) = 3/10 + 1 + 1/2 = 1,8 .
Дисперсия данной случайной величины:
D (X ) = 0,3 + 2 + 1,5 − 3,24 = 0,56 .
Математическое ожидание и дисперсия непрерывной случайной величины
Для непрерывной случайной величины механическая интерпретация математического ожидания сохранит тот же смысл: центр массы для единичной массы, распределённой непрерывно на оси абсцисс с плотностью f (x ). В отличие от дискретной случайной величиной, у которой аргумент функции x i изменяется скачкообразно, у непрерывной случайной величины аргумент меняется непрерывно. Но математическое ожидание непрерывной случайной величины также связано с её средним значением.
Чтобы находить математическое ожидание и дисперсию непрерывной случайной величины, нужно находить определённые интегралы . Если дана функция плотности непрерывной случайной величины, то она непосредственно входит в подынтегральное выражение. Если дана функция распределения вероятностей, то, дифференцируя её, нужно найти функцию плотности.
Арифметическое среднее всех возможных значений непрерывной случайной величины называется её математическим ожиданием , обозначаемым или .
Дисперсия — это мера рассеяния, описывающая сравнительное отклонение между значениями данных и средней величиной. Является наиболее используемой мерой рассеяния в статистике, вычисляемая путем суммирования, возведенного в квадрат, отклонения каждого значения данных от средней величины. Формула для вычисления дисперсии представлена ниже:
![]()
s 2 – дисперсия выборки;
x ср — среднее значение выборки;
n — размер выборки (количество значений данных),
(x i – x ср) — отклонение от средней величины для каждого значения набора данных.
Для лучшего понимания формулы, разберем пример. Я не очень люблю готовку, поэтому занятием этим занимаюсь крайне редко. Тем не менее, чтобы не умереть с голоду, время от времени мне приходится подходить к плите для реализации замысла по насыщению моего организма белками, жирами и углеводами. Набор данных, редставленный ниже, показывает, сколько раз Ренат готовит пищу каждый месяц:
Первым шагом при вычислении дисперсии является определение среднего значения выборки, которое в нашем примере равняется 7,8 раза в месяц. Остальные вычисления можно облегчить с помощью следующей таблицы.

Финальная фаза вычисления дисперсии выглядит так:
![]()
Для тех, кто любит производить все вычисления за один раз, уравнение будет выглядеть следующим образом:
Использование метода «сырого счета» (пример с готовкой)
Существует более эффективный способ вычисления дисперсии, известный как метод «сырого счета». Хотя с первого взгляда уравнение может показаться весьма громоздким, на самом деле оно не такое уж страшное. Можете в этом удостовериться, а потом и решите, какой метод вам больше нравится.

— сумма каждого значения данных после возведения в квадрат,
— квадрат суммы всех значений данных.
Не теряйте рассудок прямо сейчас. Позвольте представить все это в виде таблицы, и тогда вы увидите, что вычислений здесь меньше, чем в предыдущем примере.


Как видите, результат получился тот же, что и при использовании предыдущего метода. Достоинства данного метода становятся очевидными по мере роста размера выборки (n).
Расчет дисперсии в Excel
Как вы уже, наверное, догадались, в Excel присутствует формула, позволяющая рассчитать дисперсию. Причем, начиная с Excel 2010 можно найти 4 разновидности формулы дисперсии:
1) ДИСП.В – Возвращает дисперсию по выборке. Логические значения и текст игнорируются.
2) ДИСП.Г — Возвращает дисперсию по генеральной совокупности. Логические значения и текст игнорируются.
3) ДИСПА — Возвращает дисперсию по выборке с учетом логических и текстовых значений.
4) ДИСПРА — Возвращает дисперсию по генеральной совокупности с учетом логических и текстовых значений.
Для начала разберемся в разнице между выборкой и генеральной совокупностью. Назначение описательной статистики состоит в том, чтобы суммировать или отображать данные так, чтобы оперативно получать общую картину, так сказать, обзор. Статистический вывод позволяет делать умозаключения о какой-либо совокупности на основе выборки данных из этой совокупности. Совокупность представляет собой все возможные исходы или измерения, представляющие для нас интерес. Выборка — это подмножество совокупности.
Например, нас интересует совокупность группы студентов одного из Российских ВУЗов и нам необходимо определить средний бал группы. Мы можем посчитать среднюю успеваемость студентов, и тогда полученная цифра будет параметром, поскольку в наших расчетах будет задействована целая совокупность. Однако, если мы хотим рассчитать средний бал всех студентов нашей страны, тогда эта группа будет нашей выборкой.
Разница в формуле расчета дисперсии между выборкой и совокупностью заключается в знаменателе. Где для выборки он будет равняться (n-1), а для генеральной совокупности только n.
Теперь разберемся с функциями расчета дисперсии с окончаниями А, в описании которых сказано, что при расчете учитываются текстовые и логические значения. В данном случае при расчете дисперсии определенного массива данных, где встречаются не числовые значения, Excel будет интерпретировать текстовые и ложные логические значения как равными 0, а истинные логические значения как равными 1.
Итак, если у вас есть массив данных, рассчитать его дисперсию ни составит никакого труда, воспользовавшись одной из перечисленных выше функций Excel.




